We are creating a single taxonomy for GOV.UK, to make it easier for visitors to find what they are looking for quickly. This blog is about how we have experimented with data science to save time when building taxonomies.
The Finding Things team started the process of creating a single taxonomy with pages about education. First of all we identified the topics education content is divided into, which was manual and time consuming: but the information helped content designers audit the relevant education content. It also provided scope for building the new taxonomy which, together with data and user research, allowed us to tailor the taxonomy to meet user needs.
Since we’ll be doing similar activities for other categories of GOV.UK, we decided to investigate whether we could use data science methods to automatically generate topics for the education content on GOV.UK. We collaborated with data scientists from the Better Use of Data team who have recently completed a similar project Classifying User Comments on GOV.UK.
Topic models
The technique we used is called topic modelling. This identifies clusters of words that often occur together in a group of documents. These clusters represent topics found in the text. For instance, we found quite a few uses of the words 'years', 'child', 'early' and 'care'. From this we know these documents refer to a topic we might call 'Early years childcare'.
A document may contain multiple topics, and once we have built a topic model we can apply it to unseen documents to find topics in them.
A common way of uncovering such topics is Latent Dirichlet Allocation (LDA), a statistical method which learns the distribution of topics in a body of text. We have previously used LDA to better understand user feedback on GOV.UK.
Preparing the data
Finding and preparing data is often the most time-consuming part of any data science project.
Initially we tried to find topics in the titles of the pages but we found that it was easier to find useful topics if we used the full text of the pages. We also experimented with extracting text from PDFs embedded in pages which didn’t ’t work well because the content in PDFs was not necessarily curated to the same standards as page text.
We created a multi stage pipeline and implemented several different ways of processing the text, to see what worked best.
One of the simplest ways of preparing text is to remove common words that add little meaning, for example 'the', 'of' or 'and'. We call these stopwords. Removing these words helps us focus on the more meaningful part of the text.
As we explored our data we also started to compile a custom list of stopwords that were very common in our content, including names of countries and politicians, and words which our Information Architects decided were irrelevant.
Besides removing stopwords, there are other things we can do to reduce the complexity of the data, and make it easier to extract meaningful topics.
Stemming, lemmatization and part of speech tagging
It’s easier to find coherent topics if inflected forms of words are first reduced to their base form or lexeme. For example, 'learning' , 'learnt' and 'learner' can all be reduced to the root form 'learn'.
Stemming is a simple and quick method that attempts to find the root form by truncating words, this would work well in the example above. Lemmatization is a better solution as it takes into account the context of words and their meaning. Hence the word 'better' has 'good' as its lexeme. In addition lemmatization is able to distinguish between cases where a word may have multiple forms. For example 'meeting' which may be used a noun, with the lexeme 'meeting', or as a verb where the lexeme is 'meet'.
Before we lemmatize we first need to part of speech tag the words in our document, identifying them as verbs, adverbs, nouns, adjectives etc. We found more useful topics if we used only nouns and adjectives in our topic models.
The combination of lemmatizing and removing stop words reduces the number of distinct words we need to deal with, and makes it quicker and easier to uncover topics.
Bigrams and phrases
LDA looks at how often words occur in a document but not what words they appear with, meaning we lose information. For example, the words 'early' and 'years' individually don’t carry the same meaning as 'early years'. A simple way to capture more meaning is to generate word pairs or bigrams, 'early years' in this case, and treat this as a word.
This can be taken further by extracting longer sequences of words or phrases from the documents instead of just bigrams. We found that including common phrases in the list of words we process made it much easier to make sense of the generated topics.
TF-IDF transform
Even after stopword removal, we can still have common words that don’t add much information. For example words like 'school' and 'university' will be very common in GOV.UK pages about education. The Term Frequency - Inverse Document Frequency
transform reduces the importance of words which are common in the documents you are looking at, and gives more importance to words that appear in only a subset of documents.
Running LDA
With a processed list of words and phrases, we can then start creating the dictionary of the words and phrases we have found, together with the corpus, or 'bag of words'. The dictionary is simply a collection of unique words or phrases found in the data processing step, with associated IDs and the number of occurrences across all documents. The corpus is a list of metadata for each of the documents. Each document is represented in the corpus by pairs of word or phrase IDs, pointing to the dictionary, and the frequency count of those words or phrases in the document.
As an example, given two documents like these:
Document 1: The early years foundation stage (EYFS) sets standards for the learning, development and care of your child from birth to 5 years old.
Document 2: All schools and Ofsted-registered early years providers must follow the EYFS, including childminders, preschools, nurseries and school reception classes.
The dictionary might include words and phrases like this:
| Word/Phrases | ID |
| Childminder | 11 |
| Foundation stage | 10 |
| Preschool | 16 |
| EYFS | 4 |
| School | 14 |
| ... | ... |
And the corpus will look like this:
| Word/Phrase ID in Dictionary | Number of occurrences in corpus |
| 4 (EYFS) | 1 |
| 10 (Foundation stage) | 1 |
| 14 (School) | 2 |
| 16 (Preschool) | 1 |
| ... | ... |
In our approach, we went with either 10 or 20 topics, which seemed to be good numbers given our knowledge of the education content on GOV.UK.
LDA is an iterative process, too few iterations and the topics created may be incorrect, however iteration is a time consuming process, so simply choosing a large number of iterations is not viable.
Managing and Documenting experiments
We wanted to try out different ways of pre-processing the text and running LDA, so we built a system to manage experiments with a range of different parameters, saving important data for each one. This helped us to document our experiments and avoid re-running very slow process like part of speech tagging.
Since the results had to be evaluated by domain experts, we needed to put together the experiment in a way our Information Architect (IA) could understand and comment on. We decided to use Jupyter Notebook to document our experiments, because it allows us to write both code and free-form text, and expose the notebook via a browser for our IA to inspect.
In each experiment, we recorded details of the experiment and an interactive visualisation of the topics, using pyLDAvis, to help us understand their content and infer meaning.
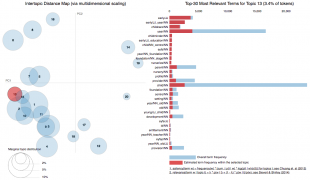
You can see the topics represented as circles on the left hand side, and the words making up those topics on the right hand side. Topics and words are clickable, allowing us to see which words are common in a topic, and which topics include a given word.
The lambda slider helps us focus on words that are distinctive to a topic. With lambda set to one, words are ranked with the most common in a topic first. As lambda is moved towards 0 words that are distinctive to that topic are given a higher ranking. Generally placing Lambda in the region of 0.5 gives the most useful information about a topic.
Finally, each experiment also showed a sample of the documents used as input, tagged to the newly generated topics. This allowed our IA to quickly check if the documents have been tagged to topics in a coherent way.
Conclusion and next steps
While we can effectively identify distinct topics using LDA, human intervention is required to identify their meaning and label them. Not all the topics found are useful for taxonomy.
In our best experiment, our IA identified 11 out of the 20 topics as being useful and mapping to existing topics, as well as not missing any of our pre existing topics. So although we will need to carefully curate topics, we expect that LDA can be used to substantially automate the process of assigning topics to documents.
The collaboration between developers, information architects and data scientists to form a cross functional team was a new way of working for all of us. We found that we got a lot more done by combining our skill sets and produced robust reusable code encapsulating an advanced level of data science knowledge.
So far, we’ve only run this on education content. The next step will be to run the algorithm on content we don’t already know about. When the Finding Things team start the next broad subject area, we’ll start by compiling a rough list of its content, then provide automatically generated topic information to our information architect and content designers, based on that content. If we find this really helps them build the next part of the taxonomy, we could consider building this functionality into our taxonomy and tagging tools.
We’ve published our code on the GDS GitHub. If you want to learn more about data science techniques we’re using at GDS, you can subscribe to the GDS data blog.
Carlos Vilhena and Mat Moore are developers and Vicky Buser is an Information Architect in the GOV.UK Finding Things team. They worked with Ben Daniels and Matt Upson, who are data scientists in the Better Use of Data team.
1 comment
Comment by Steve Foreman-Kanan posted on
Why don't departments and independent inquiries use such methods?
It really seems like they have fallen so far behind expectations of what is now pretty normal.
Imagine applying such tools to gain insight into the Hillsborough evidence?