The Government Data Science Partnership (GDSP) brings together public servants to share knowledge about data science. It’s a collaboration between the Government Digital Service (GDS), Office for National Statistics (ONS) and the Government Office for Science.
At our latest meet-up about 60 people, from more than 20 departments and public bodies, gathered in Manchester to discuss Natural Language Processing (NLP).
NLP is used to interpret unstructured text data, such as free-text notes or survey feedback. It can help us look for similarities and uncover patterns in what people have written, which is a difficult task because of nuances in sentence structure and meaning.

We’ve written before about NLP for classifying user feedback and tagging pages of GOV.UK, and the Ministry of Justice have used it to identify document relationships. At the meet-up we heard from data scientists across the public sector on how NLP is being used in their organisations.
Finding patterns
Computers can do a better job than humans at identifying patterns in text datasets. On the day, 2 data scientists spoke about their use of unsupervised machine learning to help them. This is when a computer is used to find patterns in the data without any prior information about what it should be looking for.
Dan Schofield from NHS Digital was tasked with identifying meaningful groupings from the free-text input of a nationwide dataset of appointments in GP practices. He used Python to convert his documents to numbers with Doc2Vec and simplified their complexity using an approach called t-SNE (t-Distributed Stochastic Neighbourhood Embedding). Dan fed this information into an algorithm called HDBSCAN to find meaningful groups, including one that contained appointments related to injections.
Luke Stanbra from the Department for Work and Pensions presented on using free-text data to group incident support tickets and find common root causes. Like Dan, Luke used an unsupervised approach called topic modelling to solve this problem. He discussed Latent Dirichlet Allocation (LDA) to assign texts to abstract ‘topics’ that represent word distributions and how structural topic models can improve models by taking into account document-level data.
Creating pipelines
As well as unsupervised machine learning, supervised techniques are also used for NLP. This is when an algorithm predicts a label for new data based on some data that’s already been labelled by humans with specialist knowledge.
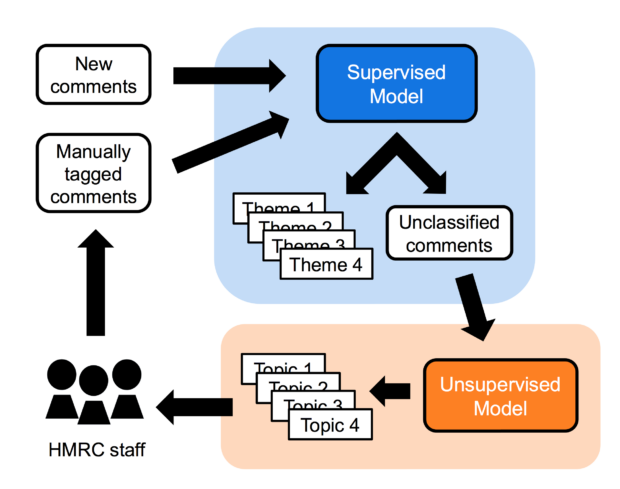
Ben Stanbury, Neil Potter and their team at HM Revenue and Customs (HMRC) used both supervised and unsupervised techniques in a pipeline to help classify and present thousands of feedback items that are received each day by the department.
HMRC staff tagged a sample of comments, and the team used this to train a supervised classification model, making use of Support Vector Machines and Gradient Boosting Machines. The model tagged incoming data when its confidence in a label was high enough. Unlabelled comments were passed into an unsupervised LDA topic model to identify emerging topics that could become new tags, ensuring data wasn’t wasted.
Summarising text
NLP is not always about grouping and labelling data based on free-text content. Data science approaches can also be used to help summarise documents.
This can be a tricky and time-consuming job for a human, so Chaitanya Joshi from the ONS Data Science Campus has explored ways to speed up and automate this process with a method called extractive text summarisation.
During his investigations, he used an unsupervised machine learning method called skip-thoughts to cluster similar sentences and select the most representative ones for each cluster. The method is based on a word-level skip-gram approach but extended to sentences. It results in a small number of sentences that best represent the whole document.
Peer surgery
After hearing the talks, attendees split into groups to ask questions and get solutions from the community about how to prepare data for NLP and use machine learning to make sense of it.
One topic discussed was a fundamental problem with text data: misspellings. For example, ‘Monday’ and ‘Mondya’ will not be recorded as the same word. Suggested solutions included the use of dictionary lookups and word-clustering algorithms.
Another group discussed an open source tool from the Data Science Campus called Optimus. Optimus takes short text records and helps to group and label them automatically.
The session closed with participants feeding back on what they’d learnt from the discussions and how they can go back to their organisations with this knowledge in mind.
Get involved
Public servants can continue the NLP conversation in the #nlp channel on the cross-government data science Slack. You can also register your interest for upcoming text analytics meet-ups by emailing the organisers.
GDSP meet-ups are open to anyone in government with an interest in data science techniques. Sign up for the mailing list or join the #community_of_interest channel on Slack. The next GDSP meeting will be in London on Thursday 27 June.

2 comments
Comment by David Underdown posted on
Hi,
How can we join the slack if our department is not in the whitelist?
Comment by nickmanton posted on
Hi David,
Unfortunately there's a limit on the size of the whitelist. We are actively trying to prune it of old domains. I've emailed you with more details.