Part II of our blog on the 4th Data Science Show & Tell focuses on sentiment analysis.
Sentiment analysis is described as the use of machine learning techniques to extract information from unstructured source materials, such as tweets, blogs etc. There is a huge potential in this type of analysis and government departments are keen to test the impact for themselves.
David Goody, from the Department for Education, showcased an example of this technique being used to understand the public response to a government policy - by examining the reader's comments on the BBC webpage for the policy announced as a 'war on illiteracy and innumeracy'.

Using R packages such as RTextTools and RCurl, in just 13 lines of code, David was able to segregate the comments in to two groups: 1) those against and 2) those in favour of the policy. Most of the comments in favour of the policy were using phrases like “back to basics”. Those responding negatively to the policy were likely to raise concerns about the impact on pupils with special needs.
Tom Hunter Smith, from the Office for National Statistics, demonstrated a second example of sentiment analysis. The aim of this project was to understand the sentiment, as expressed on Twitter, regarding the Scottish referendum. Once again with the help of R packages such as TwitteR, RCurl and Sentiment, Tom was able to group the tweets into a positive, negative or neutral category. Although many of the tweets were found to be neutral, Tom uncovered a fascinating association between the mentions of a popular soft drink and tweets on the Scottish referendum!

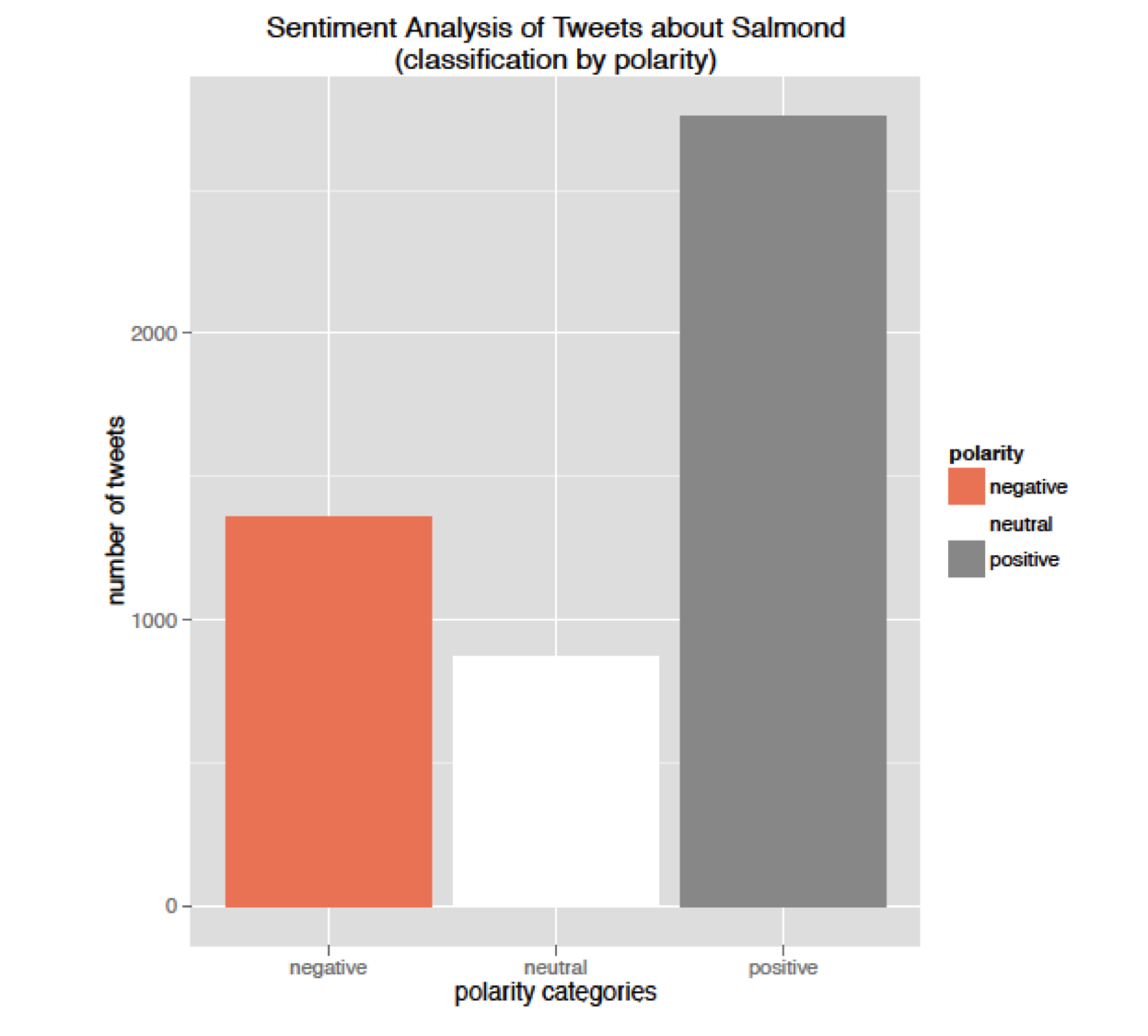
For more information on sentiment analysis and its use in government, please read our previous blog. Our next Data Science Show & Tell will be held on the 30th April 2015 from 14:00-16:00 at GDS. If you’re interested in joining us, please let us know by writing in the comments below.
2 comments
Comment by Mandy Young posted on
It sounds really interesting. Please could you add me to list of attendees for the event on 30th April. Many thanks.
Comment by Shahzia Holtom posted on
Hi Mandy,
I shall add you to the list. Hope to see you at the next Show & Tell.