Sometimes users of GOV.UK feel that we haven’t given them the best experience or told them what they need to know. We want to learn from those users so every GOV.UK page has a small form for users to tell us if and when something’s gone wrong.
Why comments are useful
The information users provide can help us understand both specific GOV.UK page issues and broader problems with whole services or types of service. We collect each comment at a page level, so that it is easy to see the history of what users have said about any one page.

So a user might comment that they couldn’t find a piece of information on a page where they expected it. If this were just one comment then we can make a call on whether changes are needed. However if there is a series of comments then this could be symptomatic of a bigger problem.
How we can analyse comments
We have previously blogged on using sentiment analysis to spot problems. We could extend this to define the 8 primary emotions of joy, trust, fear, surprise, sadness, disgust, anger, and anticipation. However, when users give purely negative feedback (i.e. if something is wrong), then the emotional range is more limited and so does not tell us as much about what users think is going wrong.
In this situation, and to understand the types of common issues users are highlighting, we can use topic modelling.
Finding hidden topics in comments
The idea of topic modelling is that each document, or each paragraph in a document, in a collection contains a mixture of topics. These topics are generated by the statistical characteristics of words within the document compared to the words in the entire collection. One topic may dominate a document or it may appear to be a mixture of many different topics. Each document is viewed as a ‘bag of words’ where word location is unimportant - it is the frequency of those words that matters.
We can use a range of techniques to try to understand topics. Commonly used ones include Latent Dirichlet Allocation (LDA), Latent Semantic Indexing (LSI) - also termed Latent Semantic Analysis - and Non-negative Matrix Factorization (NMF). In this blogpost we will look at Latent Dirichlet Allocation.
Processing the data
As with any new dataset some cleaning of the data is needed. In the case of text data, this cleaning includes removal of unhelpfully common words like ‘the’, ‘and’ or ‘of’ (called stopwords), removing punctuation and normalising words by changing them all to lowercase and lemmatising. We can also apply some probabilistic spelling correction to correct minor keying errors like ‘bnefit’ and ’chidl’.
Applying the algorithm
First, we construct a document-term-matrix (DTM). We begin by creating a dictionary of unique words. Using the dictionary we count the number of instances of a term in a document.
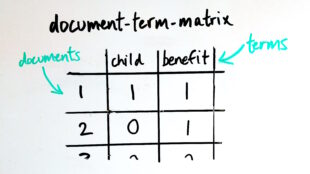
The Latent Dirichlet Allocation algorithm uses the multinomial Dirichlet distribution to define how words are assigned to a hidden or ‘latent’ topic. It begins with a random assignment of a topic to a word and then iteratively updates these assignments according to the probabilities of occurrence observed of that word within that topic and that topic within that document. The DTM matrix is used to calculate these probabilities.
After repeating this reassignment a large number of times we reach a ‘steady state’ point where words are no longer being reassigned to different topics and we stop the algorithm. You can read an informal explanation of this process (or a more in-depth technical explanation).
Defining the ‘right’ number of topics
LDA is an unsupervised machine learning method because we are not trying to fit an existing label. We could manually define topics using thematic analysis but this is an intensive and slow process that is quite subjective. Therefore a ‘ground truth’ of the correct topics does not exist.
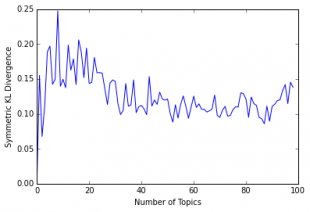
One method of defining the ‘correct’ number of topics is to use Kullback-Leibler divergence. By minimising the Kullback-Leibler divergence using this method we can try to find the statistically optimum number of topics.
Interpreting what a topic is about
Once we have defined the ideal number of topics, we need to understand what the topic is about. The quickest way is to look at the words that the LDA model says have a higher probability of appearing in a particular topic.

In this case, we can see that users are trying to complete the task of finding a way to contact a service. The use of words like ‘number’, ‘phone’, ‘email’, ‘contact’ give us a clear indication of this.
How we can use topic models in future
This approach can also be used to tackle a range of text analysis challenges within GOV.UK and across government, such as quickly understanding policy consultation responses or auto-tagging GOV.UK pages to improve search functionality. We’ll be blogging about using other data science techniques to tackle text analysis of GOV.UK survey data very soon.
6 comments
Comment by Steve Lisle posted on
Hi Dan - really interesting stuff. I'm interested in using a very similar approach for data gathered in staff surveys within the NHS. it would be great if we could speak on the phone - some more tips on doing this would be really appreciated please.
Comment by Dan Heron posted on
Thanks Steve. We will be in touch.
Comment by Tim Allan posted on
This is great. Is there a sample size threshold that makes this sort of analysis more effective?
Comment by Dan Heron posted on
Thanks Tim. The issue of sample size for this is not straightforward. As this is based on a bag-of-words concept for defining topic segmentation then more documents and the length of those documents will affect the ability to segment the topics effectively. For instance, studies of reasonably small sample sizes of a few hundred documents have shown good topic stability because the words used and length of documents gave well separated topics. This article gives an overview of some of these challenges with LDA: Understanding the Limiting Factors of Topic Modeling via Posterior Contraction Analysis
The other thing to consider is that the effectiveness of topic modelling is largely dependent on the ability for the results to be communicated and used by the business. Good analytical results don't necessarily mean that the analysis was effective!
Comment by Jake posted on
Thanks for the post Dan. This is something I've been interested in when trying to understand the topics that people contact us via email about. I have none of the technical expertise, so you're post is really helpful in understanding more about how it might be done. The real-world example about topic modelling Sarah Palin's emails was also really helpful: http://blog.echen.me/2011/06/27/topic-modeling-the-sarah-palin-emails/.
Is this something that you could setup a service (via API ideally) for departments to use to identify topics in messages as they come in? Would potentially really help us in handling them quickly and efficiently.
Comment by Dan Heron posted on
Hi Jake! The idea of providing this as a service is one we are considering. Depending on the data, there are some challenges to this such as personally identifiable information but we would be interested in hearing more about what sort of problems you are trying to tackle.