
GDS has been looking at how government can save money in business processes through the use of data standards and the interoperability they bring.
Through improving how government processes talk to each other, we can deliver users simple, seamless and connected services. We can also minimise the amount of data shared to achieve a specific purpose.
As government, we can improve productivity by reusing non-personal data that is already available, ensuring our infrastructure and services contain consistent information, and reducing unnecessary demands for data storage.
For those who work in government to analyse data sets, we can improve efficiencies and encourage more data analysis to take place, making us more aware of the impact of new policies or strategies.
Business process relies heavily on spreadsheets
People involved in the business processes put data into spreadsheets and pass them around between each other. One government department told us that their people managed data using spreadsheets around 60% of the time.
On GOV.UK alone, we found 31,121 files with spreadsheet extensions (like .ods, .xlsx or .xls) and 19,251 CSV files, many of which were not in the suggested tidy, tabular data format.
The GDS Registers team previously found users do not consider the things they put into spreadsheets to be data and we found that they treat spreadsheets just like any other office productivity tool.
Spreadsheets give their users autonomy and agency
Spreadsheets seem to give users a sense of control and allow them the flexibility they need when executing a predefined business process. Affordances such as whitespace and formatting make them easy to use.
We have recognised that people are an essential part of the business process rather than just being the owners and implementers of it. People adjust how they work and are continuously making the process safer. For example, they are able to spot potential fraud or mistakes and know how to take steps to correct things. As found by Richard Cook, the human role in the process is often as producers of information and defenders against poor data management and analysis.
Efforts to replace spreadsheets frequently fail
With this in mind, it becomes easier to understand why efforts to replace humans and spreadsheets with a more rigidly defined piece of software frequently fail.
There are often cases where people receive a digital service from their developers and all goes well for a while. Eventually they would like to make a small change to the system. They hear that this change will cost some money or perhaps take a small number of days to implement. In the meantime they go back to their spreadsheets. Because they're not in direct control of their own tools they gradually revert back to their spreadsheet-based workflows.
Therefore, not only is the most valuable government data currently locked up in spreadsheets, it looks like it will remain so going forward.
Extracting structured data from spreadsheets
Since spreadsheets are probably here to stay, We've been looking at how to extract structured data from them.
Spreadsheet programs such as OpenOffice and Microsoft Excel have a ready-made, powerful user interface and a rich data model. Users can annotate cells with information type, such as whether something is a currency and how many decimal places of accuracy they require. But when this data is exported as a CSV, much of this information is lost.
Therefore, we looked at how to extract the data directly from the original source spreadsheet files stored in open standards compliant formats.
We built a tool that takes a simple but messy spreadsheet, extracts tabular data from it, validates the correctness of each cell and then outputs the data as a JSON file that can be easily consumed by the rest of the extraction and analysis process. Once the data has been extracted and validated it could also be output as a CSV containing tabular data, along with a CSV on the web metadata file that describes it.
This allows humans to stay in control of the process while exploiting the value in data.
Extracted data becomes more useful
Data that has been extracted, becomes interoperable and more useful, and can more easily be joined and linked together with data from other sources.
Without interoperability, analysis can be limited. Metcalfe's law tells us that the value of an information network grows with the square of the number of datasets connected to it. By making a spreadsheet interoperable the data becomes more valuable and opens up opportunities for multidimensional analysis and reuse.
Defining a simple metadata language
We have defined a simple metadata language that is used to describe the data and how it can be extracted from a spreadsheet. The language itself is structured so it can be written into the first page of a spreadsheet.
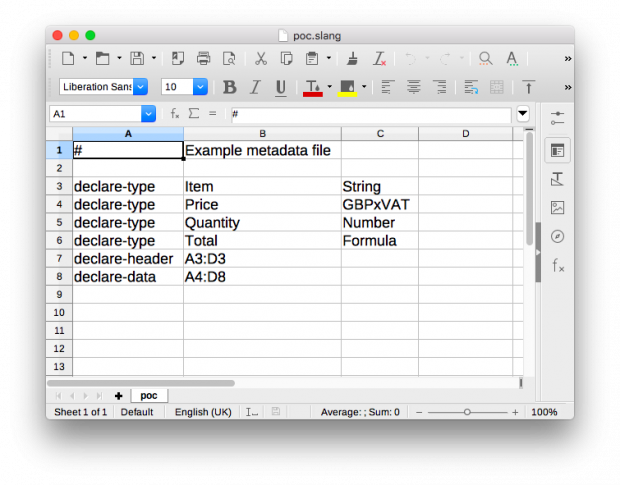
Metadata files written in this language are easy to write - they can be written either by the original author or the following users of the data. They can be shared, which makes their adoption easy and keeps the barriers to entry low.
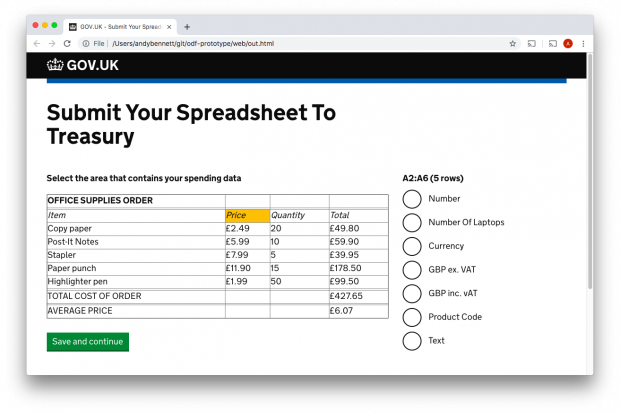
We also did some mockups of a simple service that would allow a user to upload a spreadsheet and then describe the data within it, see figure below.
Our next steps
The GDS Data Standards team is currently talking to departments about their use of spreadsheets and how consistency in extracting information can help improve interoperability.
Please get in touch if you would like to share your thoughts!
8 comments
Comment by Andy Bennett posted on
Hi Bob,
Yes we did!
We go into a bit more detail about it on the project page at https://alphagov.github.io/metadata-standards-description-language/
The aim of this work was to recognise that spreadsheets are not always tabular data. Using the tools we developed for the proof-of-concept to extract data from an arbitrary spreadsheet and format it into tabular data as specified by the standard is one of the applications that we were aiming for.
Comment by Andy Tomalin posted on
I read the reference but I don't see why you draw the conclusion here that "users do not consider the things they put into spreadsheets to be data"
On the basis of the observations you are citing, it seems to be more rational to conclude that "users consider spreadsheets are the only useful containers of data for human presentation."
Comment by Andy Bennett posted on
Hi Andy,
When we did the research behind that post we spoke to people in teams managing business processes in Government. We asked them how they did this and almost all of them used a spreadsheet. None of them used the word "data" to describe what they were doing.
When we asked them, people didn't really draw a distinction between putting things in a spreadsheet and putting things in a word doc. They knew which tool to use for which kind of work, but thought of the tools as things to help them with their work rather than as spreadsheets being something different for managing data.
In the same way as I don't consider writing a letter in a word processor as inputting or manipulating data, they didn't consider keeping track of lists of things in spreadsheets as data management.
So, whilst it's often useful for us to think about the things we see in spreadsheets as "data", we found plenty of users getting lots of value out of the tool without thinking about it in that way. Keeping this in mind can be helpful when trying to work out why data in spreadsheets often looks the way it does.
Comment by tobychev posted on
Did you have a particular reason for not using extended csv as your target format? Json seems a bit unweildly for tabular data transmission.
Comment by Andy Bennett posted on
Hi tobychev,
No, not really.
JSON was just an example for the proof-of-concept that would be recognisable to programmers as something that would be easy to process later. If extended CSV was more useful for a particular use case then that would be the correct format to output.
Once the data has been extracted and validated, the tool can be customised to produce whatever format the user requires.
https://github.com/alphagov/metadata-standards-description-language/blob/master/poc.py is the basic version that just does the extraction and validation and then leaves the rest up to the user. They don't even have to output it at all: they can just use the data directly if they want to.
https://github.com/alphagov/metadata-standards-description-language/blob/master/poc-json.py is the version that renders the data into JSON as a simple example of how it can be put into a new format.
Comment by Gareth H posted on
Hi,
In our evolution of this we transform it to CSV rather than JSON for the reasons you mention.
Please see this link, that contains links to the updated proposal and code we have done.
https://technology.blog.gov.uk/2019/06/26/help-us-improve-government-data-standards/
Comment by Bob Cerf posted on
Did you look at https://www.w3.org/TR/tabular-data-primer/ ?
Comment by Gareth H posted on
Hi Bob,
We have updated our proposal and aligned with standards more.
Please see this blog post that links to our updated proposals.
https://technology.blog.gov.uk/2019/06/26/help-us-improve-government-data-standards/
We have used Dublin core for most of the tags and aligned our syntax more closely with CSV on the web.
We have looked at this framework as well.