Defence generates and holds a lot of data. We want to be able to get the best out of it, unlocking new insights that aren’t currently visible, through the use of innovative data science and analytics techniques tailored to defence’s specific needs. But this can be difficult because our data is often sensitive for a variety of reasons. For example, this might include information about the performance of particular vehicles, or personnel’s operational deployment details.
It is therefore often challenging to share data with experts who sit outside the Ministry of Defence, particularly amongst the wider data science community in government, small companies and academia. The use of synthetic data gives us a way to address this challenge and to benefit from the expertise of a wider range of people by creating datasets which aren’t sensitive. We have recently published a report from this work.
What is synthetic data?
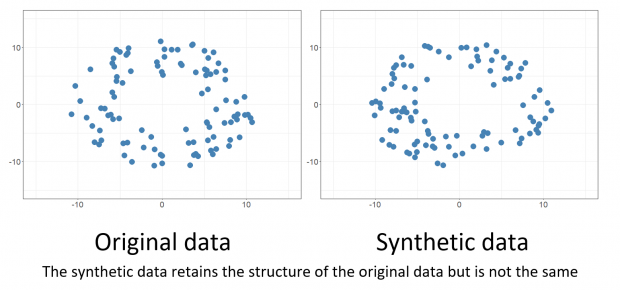
Synthetic data is artificially generated to mimic the characteristics and structure of sensitive real-world data, but without exposing our sensitivities. For example, we might want the synthetic data to retain the range of values of the original data with similar (but not the same) outliers. Or we might want to retain a similar frequency distribution in the synthetic and original datasets. However, this becomes more complex when we start to consider interactions between fields, or different types of data such as free text and GPS locations.
An example of the type of sensitive data we might see in defence and the synthetic data it might generate are below:
| VEHICLE_NO | DATE | DESTINATION |
|---|---|---|
| ZHB569 | 23/06/2020 | 51.122 latitude, -1.720 longitude |
| ZHB256 | 24/06/2020 | 51.507 latitude, -0.127 longitude |
| VEHICLE_NO | DATE | DESTINATION |
|---|---|---|
| 1 | 23/06/2020 | 51 latitude, -1 longitude |
| 2 | 24/06/2020 | Factory |
However defence is not alone in this regard as sensitive data is held by a wide variety of institutions, particularly in the medical and financial sector. As a result there is significant interest and activity in synthetic data in government and academia. For example the Office for National Statistics’ Data Science Campus has looked at using generative adversarial networks (GANs) to generate synthetic data.
What we did
Defence Science and Technology Laboratory (Dstl) has worked with BAE AI labs to understand which methods for producing synthetic data are best for different types of data. We have selected a variety of open datasets which are similar in nature to those held in defence such as:
- tabular datasets containing numeric and categorical data
- relational datasets. That is, those which contain different tables where there is a relationship between the different tables
- GPS location data
- free text data
There are a lot of different methods
The project identified around 16 techniques to obscure sensitive or private information in datasets. These include statistical methods, deep learning techniques and natural language processing for the data types above. Typically they can be summarised as falling into the following categories:
- redaction: completely removing data from the dataset
- replacing/masking: replacing parts of the dataset
- coarsening: reducing the precision of the data
- mimicking: generate a dataset that closely matches the real dataset but does not contain exactly the same entries
- simulation: generating part or all of the dataset that is similar in essential ways to the real data but is different with regard to sensitive information.
Three methods were trialled in detail. Of all the techniques studied, GAN-based techniques are the most active area of research. GANs have the potential to represent more complex distributions and relationships than basic statistical methods and can handle multiple data types within the same model. However, they can be difficult and time-consuming to train, taking up significant computational resources. Of all the other methods studied, many tools still use statistical approaches and these are being explored and extended for different data types.
Overall, the particular synthetic data generation method chosen needs to be specific to the particular use of the data once synthesised. Given the maturity of the research in this area, it is not currently realistic to use one method for all purposes.
How we can evaluate these methods
Having looked at the strengths and limitations of different open source methods for each of the types of data above, we produced a framework to assess and compare different methods. This includes considering:
- how versatile the method is to handling different types of data
- how well the synthetic data mimics the statistical properties of the original data
- how the method preserves the utility of the original data, while maintaining strong privacy levels
- how easy it is to explain and influence the method output
- how long the method takes to run and if there are specific computing requirements.
Find out more
1 comment
Comment by Michael Platzer posted on
If you are looking for evaluation criterias reg the accuracy of synthetic data, our company blog might be insightful. See eg https://mostly.ai/2020/09/25/the-worlds-most-accurate-synthetic-data-platform/ or https://mostly.ai/2020/06/05/how-to-unlock-your-behavioral-data-assets-part-iii/ for behavioral/sequential data. Plus, you are of course welcome to also use our Synthetic Data SaaS service. It just takes a few clicks to get started: https://mostly.ai/