The Data Science Accelerator is a capability-building programme which helps analysts in the public sector to develop their data science skills. The programme is supported by the Government Digital Service (GDS), Office for National Statistics (ONS), Government Office for Science, and Civil Service analytical professions.
Each analyst who is selected to take part in the programme is mentored by an experienced data scientist for the duration of the project. An important part of the programme is matching each mentee with the mentor who can best assist them.
This can be quite challenging as many of the proposed projects are complex and require a combination of data science skills. These can be specific computer languages suitable for the proposed task, machine learning techniques or experience with specific data types, such as audio/video processing.
This year, the coronavirus (COVID-19) pandemic meant that mentors and mentees had to communicate remotely. Although this was an additional challenge, it also gave us an opportunity.
Previously each mentee selected a regional hub across the country, where they would work on their project. The pool of available mentors was limited to those affiliated with this hub. With remote working, this restriction was removed and we were able to pair mentees with mentors who had the best combination of technical skills to support their projects.
The new matching process
When designing the new process, which we first applied to the last accelerator programme cohort of 2020, we had 2 main goals:
- to make the programme as enjoyable and productive as possible, both for the mentees and the mentors
- to ensure that we developed a robust process which yielded reliable results quickly, given that the matching exercise had to be completed over a short timescale
We found that this could be achieved by identifying a list of keywords in each accelerator project related to required languages, data science techniques or similar, and assigning the project to the mentor with the most relevant set of skills.
Therefore, our first step was to create a list of data science keywords relevant to the content of the applications of the programme. These keywords were organised in 6 groups, which were:
- languages (like Python or R)
- tools (such as RShiny or Dash)
- programming environments (like Azure, Google Cloud)
- data types (such as health data, video, text)
- themes (for instance COVID-19)
- data science techniques (like natural language processing, deep learning)
We then tagged each successful application with the relevant keywords. At the same time, we sent the list of keywords to the mentors participating in the accelerator programme, who specified their degree of expertise in each topic related to the keywords.
We then sent each mentor the applications which were more relevant to their expertise, based on the keywords they had selected and asked them to give us a ranked list of their preferred projects. Using each mentor’s preferences and their degree of expertise in the keywords assigned to each project, we estimated the strength (score) of the match for each mentor-mentee pair.
At this point, an obvious way to proceed would be to select the mentor-mentee pairs based solely on the strength of their match. That is, we could start by selecting the pair with the highest score, then the pair with the second-best score, and so on. This would mean, however, that our last pairs would have low scores, which would not offer a good experience to the mentee or the mentor.
For this reason, we handled the exercise as an optimisation problem, where our goal was to maximise the average strength of the mentor-mentee matches. We used the linear programming optimisation method, and first specified our problem’s constraints: for example, we required a specific number of mentor-mentee pairs, equal to the number of accepted projects; also, each of the mentors and mentees should only be present in only one pair.
We then defined our objective function (the quantity that we wanted to maximise), to be the average strength of the mentor-mentee matches. We translated our constraints and the objective function into a system of linear equalities and inequalities that described our problem. Finally, we solved the system with the PuLP open-source linear programming package and obtained the optimal list of matches.
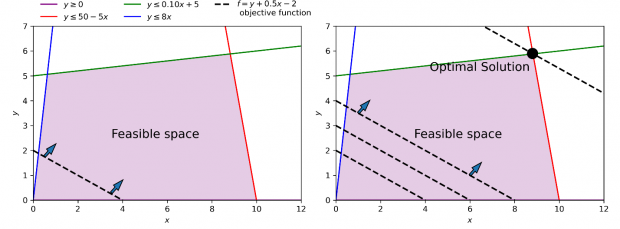
In the figure below we give a visual representation of a sample linear optimisation problem in 2 dimensions. We first visualise the problem’s constraints with a system of inequalities, which define the feasible space, or the area of possible problem solutions. We then plot the objective function (f), which we would like to optimise. This function is presented as a family of parallel lines, each of which corresponds to a different value of f. If we would like to maximise the function, the optimal solution would be the farthest line of the family from the origin, which contains at least one point of the feasible space.
Results and final thoughts
We assessed the quality of the resulting matches by comparing the mentors’ preferences to the results of the matching process. We found that 50% of the mentors were matched to their first project preference, 25% to their second, 12.5% to their third and 4.2% to their fourth. The remaining 8.3% of the mentors did not specify any preferences and our algorithm determined their matches only using their areas of expertise.
Overall, the matches were very close to the mentors’ preferences and our process considered the mentors’ expertise in specific areas. Therefore, we were confident that the obtained list of matches was of high quality and that the programme would be an enjoyable experience both for mentees and mentors. Feedback from our recent graduates has been positive and they shared their experiences of remote mentoring in a recent blog.
Additionally, we found that the new matching process proceeded very smoothly and our team was able to finalise the mentor-mentee pairs with confidence more quickly than before. Indeed, the partial automation of the matching exercise with the use of keywords and the addition of an optimisation algorithm quickened and simplified the procedure, and at the same time contributed to the generation of high-quality – and potentially more “objective” – matches.
Don’t forget that the Data Science Accelerator programme is currently welcoming new applications until 12 February. If you are interested, please apply online or contact us! Also, if you are an experienced data scientist and would like to inspire the new generation, motivate with your leadership skills and expand your professional network, please get in touch about becoming a mentor - the programme can only grow with more mentors!