A year and a half ago, two GDS Designers asked me, “Can you show us how Highway Code content on the GOV.UK site is performing?”
This would have been a simple request, were it not for the sheer number of pages that existed at that that time. You can see what it looked like on the National Archives site:

There are a number of options you may consider in solving such requests, and some are better than others:
Option One - Collect and collate the data for each page separately
This method for collecting the data would involve the following steps:
- Loading the ‘All Pages’ report in Google Analytics
- Filtering each of the relevant pages separately
- Then downloading the numerous data sets into a spreadsheet
- Finally collating all of this data into one master sheet
You would then need to repeat these steps for each type of report you need to run. For example you may need a report on referring sites, or previous and next pages, or even the list of searches made on the page.
This method is clearly not very feasible and would cause nightmares, as you’d be driven to distraction trying to keep a track of everything.
Option Two - Using regular expressions to filter
We could also use the Google Analytics Reporting API with Google Sheets and build a number of regular expressions to filter the pages. However, the 256-character limit within Google’s regular expressions means that we would have to build a lot of reports and join them together.
This method would also be problematic, as you would need to keep track of all the regular expressions and resulting tabs. This would be further complicated by the number of report types you’re using. Four reports would mean four times as many tabs!
Option Three - A better, and more exciting way!
By using an XPath expression, to navigate through elements and attributes in an XML document, we can get a list of all the links on the page that we need to report on. We can then use this to build a Python script. This script will:
- loops through the list of slugs (links on the page)
- use the Google Analytics Reporting API to get the data we need for that slug
- and then output the data to a handy csv file for analysis
This method builds on the Vin’s blog ‘How to scrape page data using the ImportXML function in Google Sheets’. Obviously I’m going to run through the third option here!
Using Python and Xpath with the Google Analytics Reporting API
There are 3 main steps for this task:
- Set up credentials and Python libraries to use with the Google Analytics reporting API
- Build a script that used the API to:
- use your credentials to access the API
- scrape the list of slugs from the /highway-code page
- get the analytics data from the Google Analytics API
- Output the results and analyse them
Setting up your environment
The first thing you need to do is create a project folder that is going to contain all Python files and all your project files. In order to do the following, you will need administrator rights on your computer.
To use the Google Analytics Reporting API and XPath in Python, you need to use the following Python libraries:
- google2pandas
- pandas
- requests
- lxml
Installing google2pandas and setting your credentials
The first step to getting access the Google Analytics Reporting API is to install the google2pandas Python library. You can follow the instructions on how to do this here. These instructions will also show you how to set up your Google Analytics credentials.
Set up your remaining Python libraries
To install the libraries:
- open a terminal window
- navigate to your new project folder
- type 'pip install pandas lxml requests'
- hit the return key
in your window you will see something resembling the following:
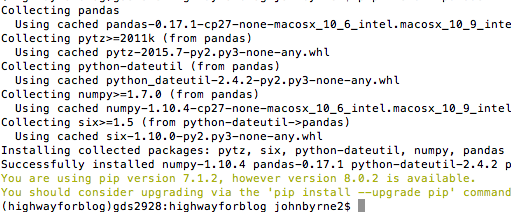
Set up and use XPath
The next step is to use XPath, which allows us to get the data we need from the web page https://www.gov.uk/highway-code.
I use a google chrome plug-in called XPath Helper which I find very useful as it allows me build the expressions I need. It shows me the XPath expression in one window and the results in another, making it easier to experiment with editing XPath expressions to get the data I want.
If you don’t want to use the Chrome extension, you can use the method described by Vin in his recent post.
If you don’t have XPath Helper, you will need to get it from the Google store.

Once it is added to your Chrome browser, you then need to navigate to the page you want to scrape. In this case, the page is https://www.gov.uk/highway-code.
Open up XPath Helper by either click on the icon on the top right of your browser.
Or hold down the Cmd Shift and X keys on a Mac, or ctrl shift X keys on a PC.
This opens up two windows on the top of the page.

To find the XPath of one slug, hover over the link and hold down the Shift key. This will show the xpath to the text of that one item.
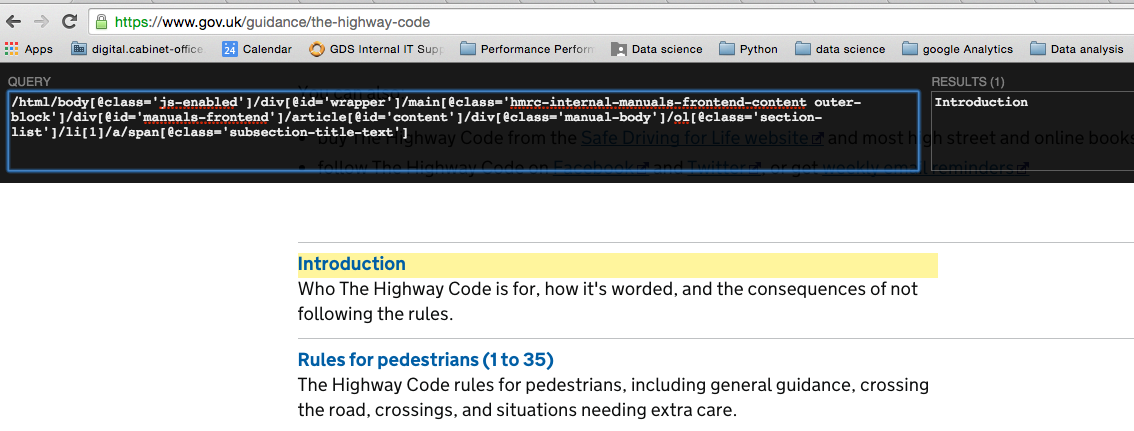
This result is not quite what we want, as we need the actual slug.
To get the slug element, we will edit the XPath expression by removing the ‘span’ section and adding ‘/@href’.
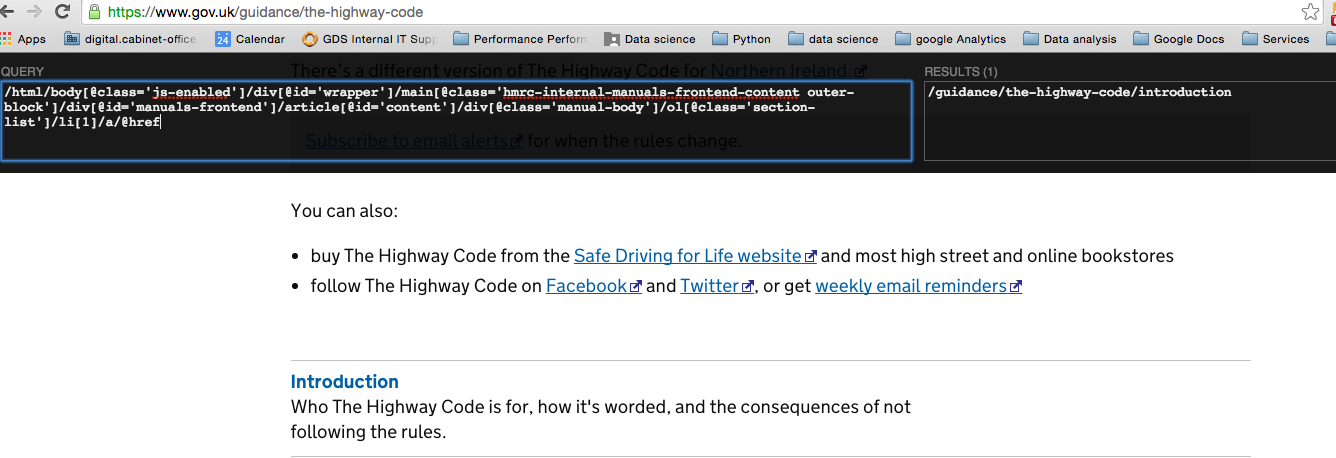
This returns one result, but we want the entire list of slugs that are on the page.
To get this we need to make one more edit and replace the li[1] entry with li[.]
The final result for the XPath expression we will use is:
/html/body[@class='js-enabled']/div[@id='wrapper']/main[@class='hmrc-internal-manuals-frontend-content outer-block']/div[@id='manuals-frontend']/article[@id='content']/div[@class='manual-body']/ol[@class='section-list']/li[.]/a/@href’
and results in the following list:
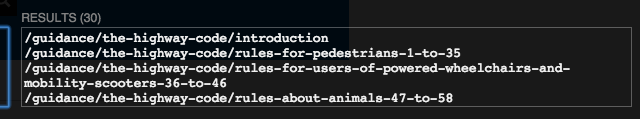
We are now ready to use this expression in our code so save it in a text file for later use.
Writing the Python script
Open up a new file in your favourite text editor, name it, and save it as a .py file.
First of all, import all the libraries that you will need:

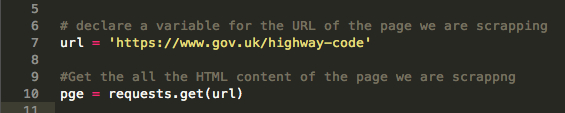
Then create a variable for the URL of the page we want to scrape.
Create another variable that holds the html of the page we are scraping:
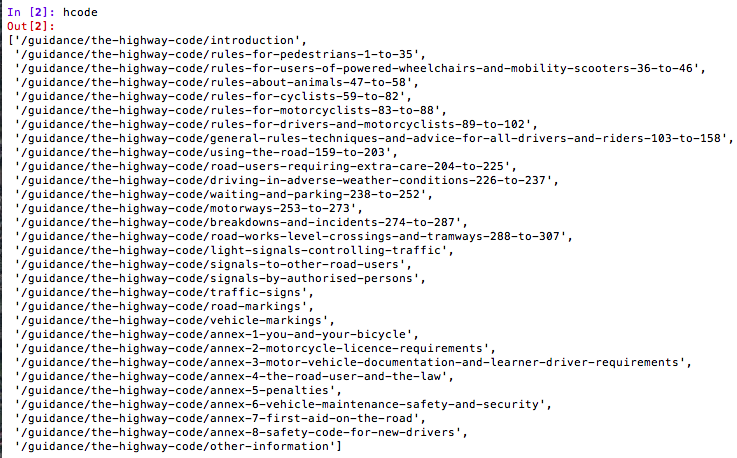
We now use the XPath expression to get the data we want from the page and hold the data in another variable called hcode.

We can use this list to get the data we need from Google Analytics.
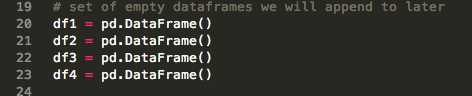
We now need to create empty Pandas dataframes variable that we will use to collect and store the metrics data from the API:
The next step is to set the dimensions and metrics as variables. These will be the actual dimensions and metrics we want to collect using the Google Analytics reporting API:
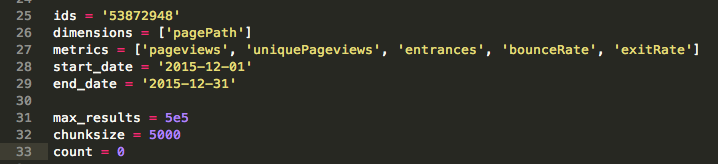
The penultimate step is to run the Google reporting API in a ‘for loop’ that runs through the list of slugs, collects the analytics data for each slug and saves it in to the relevant dataframe:
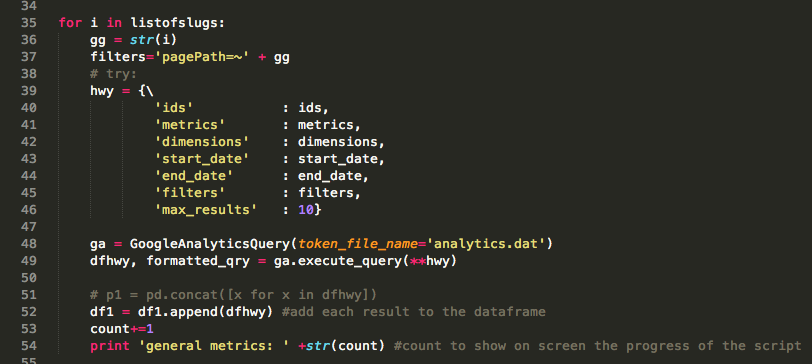
As the script loops through the list of slugs, the results are collected in a pandas dataframe. The data in this dataframe is added to the end of a dataframe called df1.
When the script have run through the list of slugs we can tidy up the data in the dataframe, do some manipulation on the data and export the data as a csv.
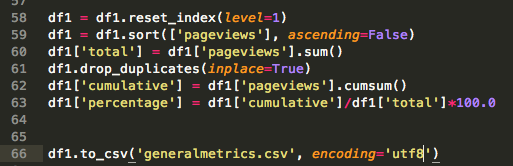
In this case we sort the dataframe using the pageviews column, add a column showing the total number of pageviews and cumulatively sum the pageviews in another column. With this data we then can create another column that calculates the percentage of the total pageviews for a particular page.
Reusable
The beauty of using a script like this is that once you have this section of code working properly you can very quickly reuse the same code again, changing it to collect different metrics and dimensions.
For example in the complete script I have quickly and easily reused this code to make separate dataframes for ‘next page’, ‘landing page’ and ‘searches on page’ reports.
The complete script is available on Github.
The result
Using my final analysis of the data the page was updated and now looks vastly different.
Please let us know your thoughts on this process in the comments below, it would also be great to hear if you or your team have done anything similar.
3 comments
Comment by Charles Meaden posted on
Thanks for some really interesting approach here.
We've done something similar using a combination of two commercial tools.
1. ScreamingFrog to extract the xpath and URLs
2. AnalyticsEdge to read the API and then combine the data
Comment by Tim posted on
Really useful guide. Thank you John.
In one of the Twitter discussions about this @so_on has posted what looks like an interesting resource containing Python libraries for web scraping and also loads for parsing and processing the data:
https://github.com/lorien/awesome-web-scraping/blob/master/python.md
Last updated a few months ago.
Tim
Comment by John Byrne posted on
Really good stuff there and all in one place - I've used a few of them with varying levels of success