When I’m doing content analysis on GOV.UK, sometimes I need to analyse page level data which is not tracked through analytics software but still represents valuable information. In these circumstances I use the ImportXML feature in Google Sheets which enables me to extract (‘scrape’) specific page data.
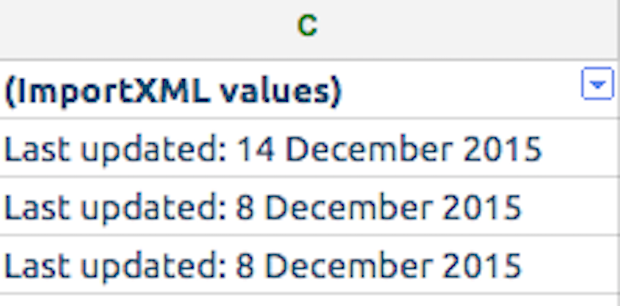
Recently, I’ve been working on a group of education content pages on GOV.UK. I wanted to be able to scrape when those pages were last updated in order to sort them based on the most recent update. The last updated information is found at the bottom of each of my pages :
However as the last updated information has no metric to track within analytics software, I used the ImportXML function in Google Sheets. My results can be found in this spreadsheet using an example of the pages that I was interested in.
Finding the XPath
The location of the last updated information is consistent across all of the pages I wanted to analyse. This is handy as ImportXML requires you to identify the XPath of the specific piece of data you want to scrape. Therefore once I was able to identify the XPath of the last updated information on one of my pages, I could implement it into the Google Sheets formula and then apply it to all of the URLs I was interested in.
Using Google Chrome, the XPath of specific page data can easily be found by highlighting and then right-clicking on it and then selecting ‘Inspect’. Firefox users can get XPath data from the Firebug add-on.
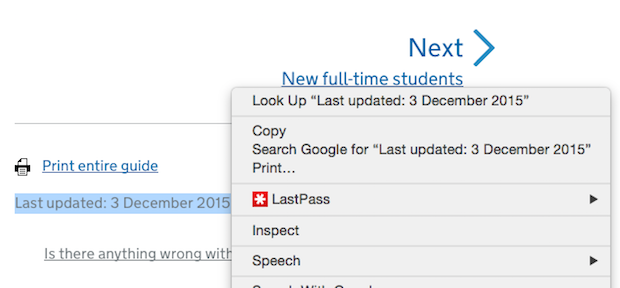
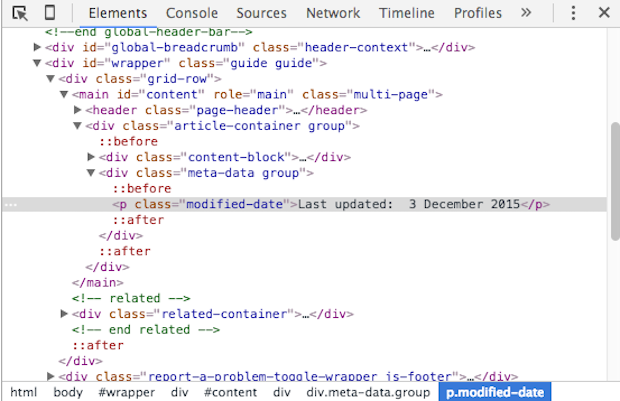
Clicking ‘Inspect’ opens up the elements console and highlights the section of the page that I am interested in. Below we can see the console has identified where the last updated information resides.
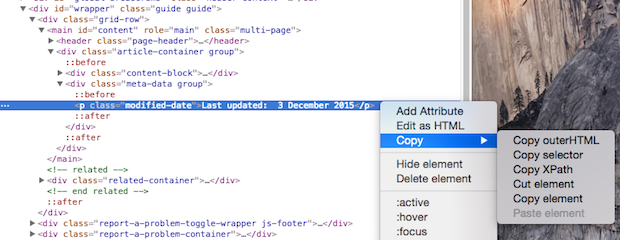
The console allows me to scrape the XPath of the last updated information by right-clicking onto highlighted section, selecting ‘Copy’ and then ‘Copy XPath’.
Creating the ImportXML formula
On the spreadsheet, in the column next to my list of URLs I entered the ImportXML formula in the format:
=ImportXML(Cell reference of URL, XPath)
![]()
I pasted the copied XPath from the Chrome console and hit enter to get the cell to show the scraped date information on my spreadsheet.
Sorting by date
Now that I have all the last updated dates for my pages, I'd like to sort them by most recently updated. To do this, I need to convert the date text string into a date value Google Sheets recognises. First, I need to remove ‘Last Updated:’ and just keep date information ‘8 December 2015’. I did this by using the MID function on Google Sheets in the next column (D):
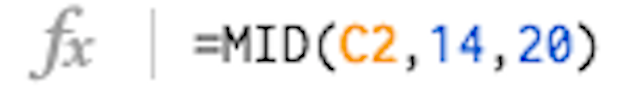
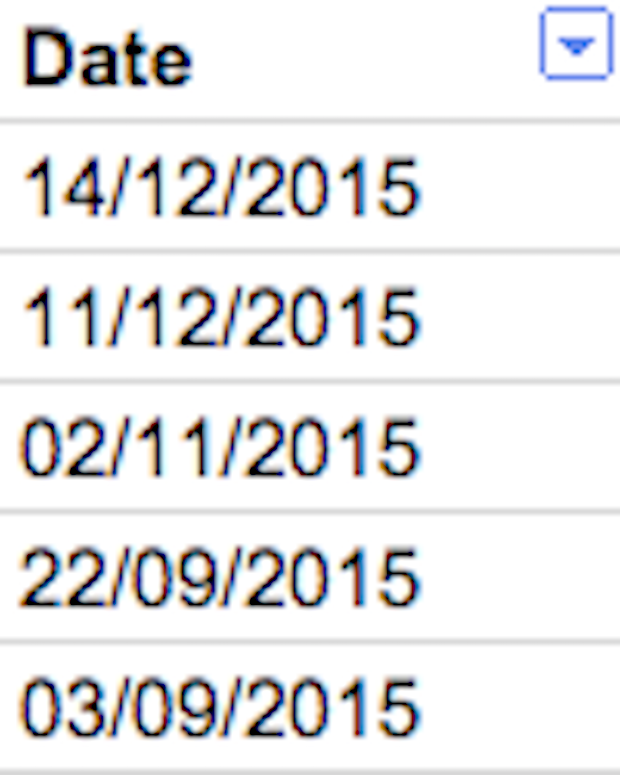
Next I needed to convert the text string date (8 December 2015) into a date value (08/12/2015) that Google Sheets could sort. Therefore I used the DATEVALUE function on Google Sheets in the next column:

Dragging this formula down the column for all your URLs provides the last updated information in a sortable format:
Application
I can use the last updated information in other relevant Google Sheets based analytics dashboards to monitor content performance following an update etc.
We're keen on hearing about your experiences of using ImportXML with Google Sheets. Please share any tips and examples you may have in the comments below.
Vin works with performance and communication analytics on GOV.UK content at GDS.
6 comments
Comment by Bill Ghere posted on
My Copy XPath doesn't look like yours in the example
//*[@id="content"]/div/div[2]/p
The structure is the same, but the details are wrong. Is this a Chrome version thing or what?
Comment by Jonathan Jones @ MoneySuperMarket posted on
Hi Bill,
I've installed a Chrome plugin called ChroPath. What you are looking for is the "rel XPath" rather than the "abs XPath" which Chrome now gives you.
Thanks!
Jonny
Comment by John Bambara posted on
Thanks for posting this.
It set me in the right direction.
I have also added some script to run the import automatically every hour, then added in script to show last update time.
function getData() {
var queryString = Math.random();
var cellFunction1 = '=IMPORTXML("' + SpreadsheetApp.getActiveSheet().getRange('B2').getValue() + '?' + queryString + '","'+ SpreadsheetApp.getActiveSheet().getRange('C2').getValue() + '")';
SpreadsheetApp.getActiveSheet().getRange('D2').setValue(cellFunction1);
}
B2 is the web address reference, C2 is the Xpath, D2 is where i put the result.
Comment by James Tuller posted on
Hello - I'm attempting to pull in the 5yr dividend yield from reuters on a list of 30 stocks. I've got the xpath, but having trouble. The stock ticker is in cell a2- =ImportXML(http://www.reuters.com/finance/stocks/financialHighlights?symbol=&a2&, //*[@id="content"]/div[3]/div/div[2]/div[1]/div[6]/div[2]/table/tbody/tr[3]/td[2])
Comment by David Saunders posted on
Thanks Vin,
does this formula's fundamentals also work when the date modified field is part of a meta / dublin core tag?
<meta name="DCTERMS.modified" content="2015-06-24T09:27:57+10:00" schema="DCTERMS.ISO8601" />
Comment by Alex posted on
Hi Vinith, thank you for the article. Great peace of advice as always.
How do you overcome the problem of constant "Loading" or not proceeding the formulas in Google Spreadsheet at all? Do you have any remedy to that if lets say one wants to gather data from 1.000 URLs?
Thank you in advance,
Alex