Representing text as vectors
We can represent the text on each GOV.UK page as a semantic vector. This is denoted by a list of numbers, which conveys information about the page contents.
We tried a few ways to develop these semantic vectors, like Gensim’s Doc2vec, fine-tuning the BERT pre-trained base model and Google’s universal sentence encoder.
The latter uses a deep averaging network (DAN) encoder trained on text from a variety of sources. It outperforms Doc2vec in the STS benchmark and was quick to implement, so we selected it for use in solving GOV.UK problems.

Each semantic vector represents a content item and the cosine of the angle between the vectors is called ‘the cosine distance’. The smaller the angle, the more similar the items are, and vice versa.
Measuring vector similarity
The position of semantic vectors in the vector space tells us about their meaning. Neighbouring vectors represent pages that are similar to each other, and distant ones denote pages that are different.
We can measure how similar 2 items of content are to each other by using the angle created by their respective vectors. The similarity score is called ‘the cosine distance’, and is calculated by taking the cosine of the angle between the two vectors.
As expected, content items which are more similar will have a smaller angle between them and thus a larger similarity score, and vice versa.
Identifying duplicate content with vector similarity
Over the last 6 months, 700 content items have been published on GOV.UK per week. This high publishing rate can result in multiple content items being published to serve the same user need. This is unnecessary and confusing for users.
Semantic similarity can identify duplicate content, and can inform publishers where their content overlaps with pre-existing content. This can be done at the publication stage – to prevent duplicate content arising – as well as retrospectively – to clean up existing duplicate content.
Informing decisions about the topic taxonomy
One important characteristic for our content is the taxon is organised in the topic taxonomy. The taxonomy is currently structured like a tree with each topic representing the aboutness of the content tagged to it.
We are still iterating both the structure and tagging approach for the topic taxonomy, and there are various ways that the semantic vectors can be used to inform decisions about changing the taxonomy.
We can identify problem branches in the topic taxonomy by calculating the average cosine distance across all pairs of content in a taxon, and use this as a metric for taxon diversity. Knowing how diverse the content is helps us to diagnose taxons which are too broad and identify possible clusters of content (for example, using DBSCAN) that warrant their own taxon.
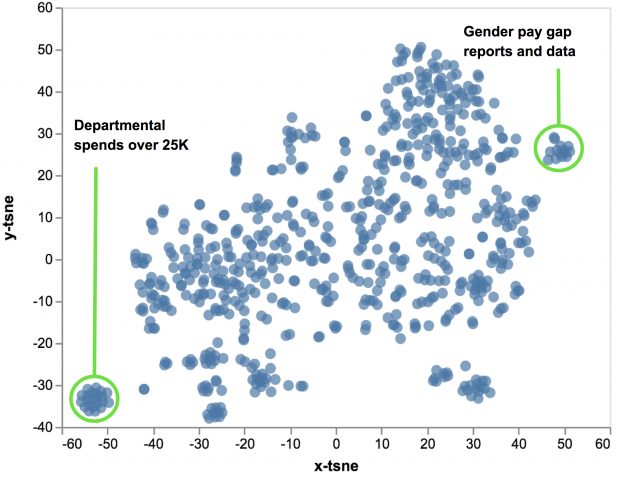
A 2D t-SNE representation of the semantic vectors of all content in the corporate information taxon of the topic taxonomy. Some distinct clusters of content exist that could potentially form new lower-level taxons.
Optimising search and navigation
There are various ways in which we can improve our site search and navigation, if our content were better organised and tagged with appropriate metadata. One approach we have been exploring is the use of automatically generated related links, displayed on the right-hand side of GOV.UK pages, to help people get to and explore the content they need.
Our first experiment to generate these links used the semantic vector representation of content to display the most semantically similar pages to each page.
But more on this soon!