GOV.UK is the main portal to government for citizens. It enables users to interact with government in a number of situations, from applying for their first driving licence to checking foreign travel advice before jetting off into the sun. With all of the content that’s required to support these tasks, it can be hard for users to find the relevant content they need.
To help users get to the information they need, GOV.UK uses a number of navigational aids – one of them being related links. Related links are shown to the right-hand side of content on a page, linking to other pages which may be of interest.
Currently only around 2% of the entire content on GOV.UK, or 8,000 pages, actually have related links. The rest have no related links at all. This matters because observation and analytics tell us that good related links result in shorter user journeys, enabling users to find the content that they need faster and with ease.
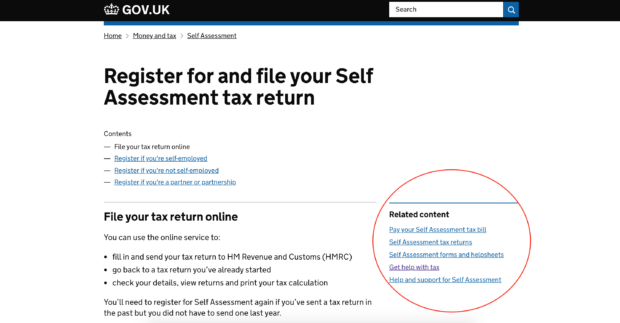
So, to improve users’ experience, we investigated whether we could use machine learning on GOV.UK to generate related links for the remaining 98% of content that had none. As a result of this experiment, we decided to implement the node2vec algorithm.
The journey to productionising related links
To productionise, at its simplest, can simply mean to move some algorithm or software into an environment where it’s used to shape the outcome of a process, later consumed by users. When applied to data science, this involves creating a joined-up and automated pipeline from individual steps, such as obtaining input data, running a machine learning algorithm and creating useful output.
Designing such a system for GOV.UK required considering a number of different problem areas to find the best trade-offs for GOV.UK itself, for GDS, and for similar projects within wider government in the future. In this post, you will read about just a few of the considerations we needed to make during the course of the project.
Hosting and running machine learning
The first choice we had to make was how we’d host the node2vec machine learning algorithm. Many cloud providers offer what’s called a virtual machine, which – to make an analogy – is simply a computer in the cloud. You can use it to install code libraries, run your machine learning and store the results somewhere. Virtual machines are popular and used widely throughout industry, including to host GOV.UK.
A popular alternative to virtual machines is serverless. Serverless is a model in which you don’t need to worry about how you host your application – meaning the infrastructure on which it runs. Serverless can host everything from fully-fledged websites to ad-hoc, infrequent tasks, alleviating the need for maintenance of the operating system on which it runs.
We chose to use a virtual machine for hosting our machine learning algorithm. Serverless is a popular and exciting technology but our development process for it isn’t fully defined. Virtual machines also act as a stepping stone towards running our applications in containers (think Docker), something that we’re actively looking into at GDS.
Jupyter notebooks meet Python
Data scientists at GDS use Jupyter notebooks for the rapid development and prototyping of solutions to data science problems. In particular, it allows code, documentation and data to live in a single place, which helps to improve both understanding and knowledge sharing between colleagues. From a developer perspective, it’s analogous to an integrated development environment (IDE), like that of Visual Studio or IntelliJ – a tool which makes the process of writing high-quality software easier through various integrations such as offering code optimisations and providing real-time debugging.
To automate the process of generating related links, we decided to modularise the code from the Jupyter notebooks and write it in object-oriented Python. We borrowed the approach of test-driven development (TDD) from software engineering to focus the development process and ensure functional code.
Ensuring quality links
One of our goals was to automate the process of generating related links. To do this, it’s necessary to have confidence in the entire process – both now and in the future. Our related links are based on a combination of how pages on GOV.UK are linked to each other and users’ behaviour on the site over a number of weeks. This means we’ll always be adapting the links we’re generating and the pages we’re generating them for.
In order to ensure a high quality of related links on GOV.UK, we added a number of steps to our process. Firstly, there are a number of pages that we never want to generate related links for or to, which we exclude at both the input and output stages of the link generation process. Next, we apply a confidence threshold to the links generated by node2vec, only allowing through those links that have a good chance of being relevant for a particular page. Finally, we generate a spreadsheet of the top 200 most popular pages, allowing our content designers to critique the related links that have been assigned to these pages and make changes where necessary.
Rolling back links
As part of productionising related links, another issue that needed consideration was what should happen if things go wrong, particularly with regards to the links that we suggest to users. This was an important consideration as GOV.UK is the digital face of government, meaning we need to ensure accuracy and relevancy at all times.
With this in mind, we decided to create and store suggested links alongside existing related links for each content item, using a new property in the content schema. This was how we implemented our A/B tests and allowed us to switch between the control and test variants of related links via our content delivery network (CDN). We implemented a similar mechanism (called an operations toggle) via our CDN to show suggested related links. This allows us to switch off these links sitewide, which might be necessary if we detect a batch of bad links has been ingested, or similar.

Generating related links as standard
Since completing the work to productionise related links, we have been running the process every three weeks and using the links generated to update our content store. Our generated related links are automatically displayed on GOV.UK when publishers haven’t set their own links, ensuring we do as much as possible to help users find the content they’re looking for.
Next steps
We’re continuously iterating and refining the related links process, and monitoring results to ensure users’ experiences are improving. In the future, there’s the opportunity that we can bring the model online and use it as part of the publishing process, helping editors creating new content to add relevant related links. All of our code is available to view on GitHub.
If you'd like to know more about how we productionise related links and what we're doing next, please get in touch in the comments below