A common data quality problem is to have multiple different records that refer to the same entity but no unique identifier that ties these entities together. For example, customer data may have been entered multiple times by accident, or have been entered in multiple IT systems separately.
Record linkage (sometimes known as entity resolution, or data matching) is a technique to link these records, enabling data to be deduplicated and joined between systems.
At the Ministry of Justice, we have developed an open source library called Splink to improve our record linkage methodology. This has enabled us to share new linked datasets with accredited researchers, as part of the ADR UK-funded Data First programme.
What is Splink?
Splink is a free library for fast and accurate record linkage, which is now in its third version. It has the following key features:
- Faster and more accurate than other free tools
- Able to link huge datasets, of tens of millions or records or more
- Its development has benefitted from guidance from our academic advisors - three professors who are experts in data linkage
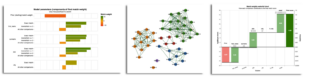
- The software produces a wide range of interactive data visualisations that help to build effective models, explain linkage predictions, diagnose problems, and quality assure models
- The software is compatible with multiple databases and big data processing engines, meaning it can run on a wider range of computer systems.
- Capable of linking a wide variety of data, and makes no assumption about the entity type you need to match
How do I get started?
Splink is a free Python package that can be installed in the usual way - using ‘pip install splink’.
We recommend users start by looking at our online tutorial, which is part of our main documentation website. The tutorial runs through a full record linkage example, from exploratory analysis right through to prediction and graph analytics, and it can even be run interactively in your web browser.
How it works
Splink is an implementation of the Fellegi-Sunter model. The software generates pairwise record comparisons using an approach called blocking, and computes a match score for each pair which quantifies the similarity between the two records.
The match score is determined by parameters known as partial match weights. These quantify the importance of different aspects of the comparison.
For example, a match on date of birth lends more evidence in favour of two records being a match than a match on gender. A mismatch on postcode may provide weak evidence against a match because people move house, whereas a mismatch on date of birth may be stronger evidence against the record being a match.
This simple idea has a lot of power to build highly nuanced models. Partial match weights can be computed for an arbitrary number of user-defined scenarios, not just a match or non match. For example, a partial match weight can be estimated for a scenario where postcodes do not match, but are within 10 miles of each other.
These partial match weights are combined into an overall match score, which represents the weight of evidence that the two records are a match.
A more detailed video description of how this all works can be found here.
Get in touch
If you work for the government and would like help getting started with your data, please don’t hesitate to get in touch at robin.linacre@digital.justice.gov.uk. You can also ask us a question or raise an issue against the main (public) github repository.