Our diverse range of speakers at the Data Science Community of Interest shared what they think makes a good data science project.

What is the data science project lifecycle?
Data Science is the practice of bringing together maths, domain knowledge and computer science to provide analytical or operational insight.
Wenda and Sam, Delivery Managers at the Office for National Statistics (ONS) Data Science Campus, gave us an overview of the data science project lifecycle in their organisation.
All proposals are pitched to the portfolio board, which determines the project's value. The project enters the exploration process after the pitch has been accepted. The exploration process allows you to iterate, double-check, prepare, and settle on its scope. Following that, the project is presented to the portfolio board, which approves its transfer to completion. To help actualise the project's benefits, the team employs agile delivery practises, such as sprint goals and user stories. You can view Data Science Campus Projects on their github page.
So what makes a good data science project?
Data ethics is a team practice
Natalia, Head of Data Ethics at the Central Digital & Data Office, Cabinet Office, presented on the Data Ethics Framework and how the framework supports responsible innovation by helping public servants to understand and address ethical considerations in their projects.
The framework provides project teams 3 guiding standards: transparency, accountability, and fairness. In addition, the following 5 steps need to be implemented during the project lifecycle:
- define and understand public benefit and user need
- involve diverse expertise
- comply with law, for example GDPR
- review the quality and limitations of the data
- evaluate and consider wider policy implications
Developing together
Jon, Senior Data Scientist at the Department for Work and Pensions (DWP), presented on Universal Credit’s A/B testing framework. The A/B testing framework randomly splits users into groups that receive variations of features such as content, site journeys and contact strategies. The results of each trial inform the development of the service, enabling further support for claimants.
Developing together with internal and platform stakeholders, the project benefits from a wide range of expertise. Jon shared with us how his team overcame challenges of implementing A/B testing. Firstly, the allocation of participants was randomly allocated to the test and control the group. Secondly, since manual collection at scale is impractical and prone to errors, the team implemented the A/B test through the digital service using the Universal Credit database. Finally, the team created an analytical pipeline of peer-reviewed evaluation tools to produce documentation of results. This enabled consistency in techniques and statistical standards and as a result stakeholders had greater confidence in results.
Better data for better decisions
Robin, a senior data scientist at the Foreign Commonwealth and Development Office (FCDO), spoke about a new dataset he created called Population Weighted Density that he created with colleagues at WorldPop. This is a different way of looking at population density that is more suited to social science and epidemiology studies.
Robin and team built on existing work to utilise 3 distinct methods arithmetic mean, geometric mean or median to develop the new dataset. The team believes out of the 3 geometric mean is the most robust metric, as it tends towards the median value and therefore is less vulnerable to outliers. You can access the datasets and learn more on the WorldPop website.
Reproducibility and Quality Assurance
Alex and David, from the Best Practice and Impact Team at ONS, launched the first draft of the Quality Assurance of Code for Analysis and Research. Building on the work of the Aqua book, the guidance supports analysts seeking quality assurance and reproducibility of their code. This living document covers topics such version control, peer-review and data management. If you have any feedback you can get in touch via github issues or email.
Consult and empathise
During our lightning talks, panel colleagues described different factors that make a good data science project.
Laurie, Head of Faculty at the Data Science Campus, kicked off the lightning talks by highlighting some questions that can help when detecting data science opportunities. View all of the questions from Laurie’s presentation on our Knowledge Hub net library.
Matt, Lead Data Scientist from GOV.UK at GDS, explained what changes a data science project from good to great is the importance of centering around user needs, and creating a simple working solution before moving forward. He highlighted their govcookiecutter template, which provides a lightweight, agile-like approach to quality assurance and helps quickly set up standardised project structures.
Kimberley, Lead Data Engineer at the Ministry of Justice (MoJ), shared with us an empathy map on data engineers. Data engineers at MoJ provide colleagues with reproducible, timely, auditable, and stable data streamed from source systems at a sufficient high frequency through MoJ's Analytical Platform. Data engineers are essential for data science projects. When creating data pipelines, data engineers consider the stakeholder’s needs by holding frequent reviews and user testing, and also the security of the data acquired. This ensures use of appropriate tools when putting work into production.
Alex, Head of Data Strategy, Probation Reform at MoJ, discussed how her team is integrating digital and data science teams during the delivery of projects, starting with an empathy map of digital product managers. To support data scientists and digital product managers, Alex has recently introduced 2 new roles: a data strategy manager and a data science product owner. The data strategy manager embeds within the digital team to improve data quality at source. And the data science product owner helps the data scientists identify the problem areas they should be focussing on. The team is seeing early results in facilitating the needs of digital and data teams in providing possible solutions to business problem statements.
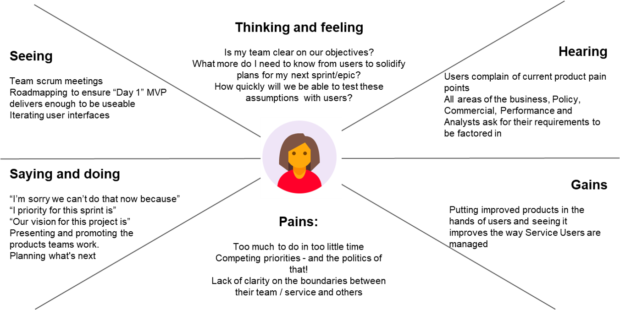
So in summary, a good data science project is a team effort that incorporates understanding of user needs, sound methodology, ethical practices and quality data piped through to data scientists to serve the public good.
Interested in learning more about making good data science projects?
Have a look at the Ethics, Transparency and Accountability Framework for Automated Decision-Making framework on GOV.UK by The Central Digital and Data Office and the Office for AI and get involved with the Data Science Community!